RAG(検索拡張生成)とは? LLMの精度を最大化する活用法を解説

無料ウェビナーのお知らせ

開催日時
2026年6月25日(木)12:00〜13:00
このウェビナーで得られること
- 海外の最前線(SMX Advanced)で議論されているAI検索/LLMO対策の最新動向
- 日本のLLMO対策と海外の現在地の違いがわかる
- 明日から実践で使えるLLMO対策のTipsが手に入る
自社の膨大なデータを活用してLLM(大規模言語モデル)の精度を高めたいけれど、RAGの実装方法や具体的な導入ステップが分からずに悩むケースは少なくありません。
本記事では、RAG(検索拡張生成)技術を活用して、自社の知識ベースを拡張する具体的なプロセス・方法を解説します。
自社のドキュメントや顧客データを活かした精度の高いAIシステムを構築し、競合他社に先駆けて業務効率化を実現しましょう。
LANYでは、「未来の顧客接点を作る、LLM最適化」をご支援するLLMOコンサルティングサービスのご提供や、以下のような無料お役立ち資料をご用意しています。
LLMOの考え方について詳しくは、こちらの記事で解説しています。

RAG(検索拡張生成)とは?
RAG(読み方:ラグ)とは、「Retrieval-Augmented Generation」の略称で、日本語では「検索拡張生成」と訳されます。RAGは、LLMが応答を生成する前に、外部のデータベースや文書から関連情報を検索し、その情報をもとに回答を作成する手法です。
この手法により、LLM単体では難しかった最新情報や、特定の専門知識に基づいた正確で信頼性の高い応答生成が可能になります。
RAGの重要性
RAGが重要視される理由は、LLMの根本的な課題を解決し、活用範囲を大きく広げられる点にあります。LLMは非常に高度な文章生成能力を持ちますが、いくつかの弱点も抱えています。たとえば、以下のとおりです。
- 「ナレッジカットオフ(生成AIが学習に使った情報の最終時点)」が最新ではない
- 事実に基づかない情報を生成する「ハルシネーション」の問題
- 特定の企業や業界特有の専門知識は、学習データに含まれない場合がある
これらLLMの課題に、RAGでは対応可能です。応答生成前に外部の最新情報や社内文書などを検索することで、常に新しい、あるいは特定の知識に基づいた応答を可能にします。
また、事実に基づいた情報を参照するため、ハルシネーションのリスク抑制にもつながります。参照した情報源を明確に示すことで、回答の透明性も高まるでしょう。
このように、RAGによって、LLMの言語能力と外部情報の正確性・最新性を組み合わせた相乗効果を生みます。LLMをより信頼でき、ビジネスで活用しやすいAI技術へと進化させるでしょう。
RAGとファインチューニングの違い
LLMの知識や能力を特定の目的に合わせて強化する方法として、RAGの他に「ファインチューニング」という技術があります。
この二つは目的や仕組みが異なります。主な違いは、以下のとおりです。
| RAG(検索拡張生成) | ファインチューニング | |
|---|---|---|
| 知識の扱い | 外部から動的に取得 | 内部パラメータに静的に埋め込み |
| 知識更新 | 外部DB更新(低コスト) | モデル再学習(時間がかかる/高コスト) |
| 主な得意分野 | ・最新情報 ・事実性 ・出典明示 ・特定文書参照 | ・スタイルやトーン調整 ・暗黙知学習 ・特定タスク特化 |
| 主な課題 | ・検索精度への依存 ・検索基盤の運用コスト | ・学習コスト ・知識の陳腐化 ・汎用能力低下リスク |
RAGは、LLM自体は基本的に変更せず、応答を生成する「都度」、外部から最新情報や専門知識を検索してきて、それを参考に回答を作成するアプローチです。
一方で、ファインチューニングは、特定のデータセットを使ってLLMを再トレーニングし、特定の知識や専門用語などをLLM自体に学習させるアプローチです。
RAGは外部データベースを更新すれば最新情報に対応できますが、ファインチューニングは新しい情報を反映させるために再学習が必要となり、時間とコストがかかります。
応答情報の最新性や事実確認、出典が必要な場合はRAGが適します。特定の応答スタイルや深い専門知識の埋め込みが必要な場合は、ファインチューニングが有効でしょう。両者を組み合わせたハイブリッドな方法も存在します。
RAGの仕組み
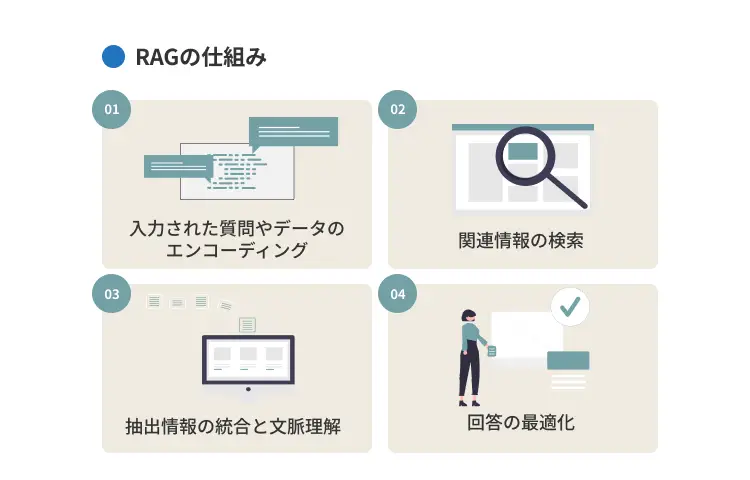
RAG(検索拡張生成)は、LLMの応答精度を高めるための重要な技術です。
本章では、RAGがユーザーの質問を受けてから回答を生成するまでの仕組みを、以下4つの主要フェーズごとに解説します。
- 入力された質問やデータのエンコーディング:AIが検索可能な形式に変換する
- 関連情報の検索:AIが外部の知識源から必要な情報を探し出す
- 抽出情報の統合と文脈理解:探し出した情報と元の質問を組み合わせてAIに提示
- 回答の最適化:AIが生成する回答の質を高めるための調整
AI検索の仕組み(RAG、クエリファンアウト)や、AI時代のコンテンツ戦略については以下の動画でも解説しています。こちらもぜひご確認ください。
1.入力した質問やデータのエンコーディング
まずは、ベクトル検索を活用したRAG(検索拡張生成)について解説します。
RAGシステムにおいて、ユーザーからの質問や指示(クエリ)を処理する最初の工程はエンコーディングです。私たちが日常的に使う自然言語で書かれたテキストを、コンピューターが処理可能な数値データ、「ベクトル」と呼ばれる形式に変換する作業を指します。
変換には「埋め込みモデル(Embedding Model)」という専用のAIが用いられます。エンコーディングを行うことで、単語や文章が持つ意味が数値のベクトルとして表現され、コンピューターはテキスト同士の意味も計算可能です。
たとえば、「RAGのメリットは?」という質問は、その意味内容を反映したベクトルに変換されます。このベクトル化された質問があることで、次のステップである関連情報の検索が、単なるキーワードの一致を超えて、意味に基づいた精度で行えます。
2.関連情報の検索
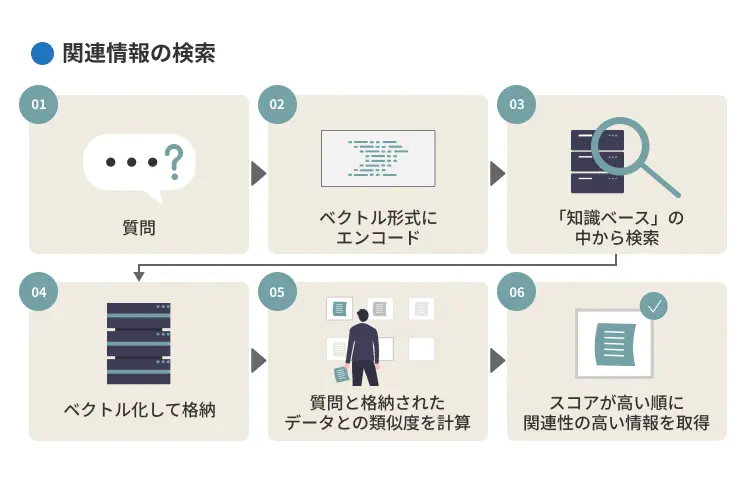
質問がベクトル形式にエンコードされると、システムは次に「関連情報の検索(Retrieval)」を行います。エンコードされた質問ベクトルを手がかりにして、あらかじめ用意された社内文書やFAQなどの「知識ベース」の中から、質問内容と意味的に関連性の高い情報を探し出します。
検索対象となる文書は、一定の長さや構造単位で分割・整理されたうえで、ひとつひとつをベクトル化して格納されます(例:段落や文単位など)。システムは、質問と格納されたデータとの類似度を計算し、スコアが高い順に関連性の高い情報を取得します。
3.抽出情報の統合と文脈理解
関連情報を検索によって取得した後、次にそれらの情報をLLMが利用できる形に整える統合を行います。この段階では、検索で見つかった関連性の高いテキストの一部と、ユーザーが最初に入力した質問が一つに組み合わされます。
これらが組み合わされたものが、LLMに対する指示書となる「拡張プロンプト」です。LLMに入力するテキストとして、まず取得された関連情報を配置し、その後にユーザーの質問を続けるといった形式が主に用いられます。
拡張プロンプトにより、LLMは単に質問に答えるだけでなく、提供された外部情報を踏まえた応答を生成するようになります。たとえば、プロンプトを以下のように構成することで、LLMは応答生成の際に参照すべき文脈を理解できます。
| 以下の情報を参考に回答してください。 参考情報:[取得した関連テキスト] 質問:[ユーザーの質問] |
このようなステップがあることで、LLMの応答が具体的な外部情報に裏付けられ、より信頼性の高いものになるでしょう。
また、より高度な手法として、LLMに回答を生成させる前に関連性の高い検索結果に並べ替える「リランキング」や、生成された回答に不適切な内容や誤情報が含まれていないかをチェックする「ガードレール」と呼ばれる仕組みもあります。
4.回答の最適化
RAGプロセスの最終段階では、拡張プロンプトを受け取ったLLMが回答を生成し、回答をさらに最適化する工夫が行われます。LLMは提供された情報と元の質問に基づいて応答を作成しますが、出力内容が常に完璧とは限りません。
冗長であったり、要点が不明瞭であったり、あるいはユーザーが求める形式になっていなかったりすることもあります。そのため、最終的な回答の質を高めるための「最適化」が重要です。
最適化の一般的な手法には、LLMへの指示(プロンプト)を調整する「プロンプトエンジニアリング」があります。以下のような具体的な指示を与えることで、生成される回答の正確性や形式を制御可能です。
- 検索された情報のみを根拠としてください
- 回答は箇条書きでまとめてください など
RAGのメリット
LLMは非常に強力ですが、単体では限界もあります。RAGを組み合わせることで、LLM単体では得られない情報を得られるほか、以下のようなメリットもあります。
- ユーザーニーズを理解した自然な文章生成
- リアルタイムの情報取得・更新
- 機密情報の漏えいリスク軽減
- 学習データの維持・管理コストの削減
ユーザーニーズを理解した自然な文章生成
RAGは、LLMが生成する文章の質を高め、ユーザーの具体的なニーズにより合致した、自然で分かりやすい応答を作成するのに役立ちます。
LLMは元々、流暢な文章を生成する能力に長けています。しかし、質問の背景にある文脈や必要な情報が不足していると、回答が一般的すぎたり、的外れになる場合もあります。
RAGは、まずユーザーの質問に関連性の高い具体的な情報を外部から検索してきます。この検索された情報(コンテキスト)をLLMに提供することで、LLMは何について応答すべきかをより明確に理解できるようになるのです。
たとえば、顧客から特定のエラーコードに関する問い合わせがあった場合、RAGが関連マニュアルから解決手順を検索し、LLMに渡します。
LLMはその手順情報に基づいて、以下のような具体的な指示を自然な文章で生成することが可能です。
| エラーコードXXXが表示された場合、まず〇〇をご確認いただき、次に△△を実行してください。 |
このように、RAGが提供する文脈によって、LLMの文章生成能力がユーザーの課題解決に直結する形に活かされます。
リアルタイムの情報取得・更新
RAG技術が持つ重要なメリットとして、常に最新の情報に基づいて応答できる点が挙げられます。
LLMの知識は、その学習データが収集された特定の時点で固定されています。そのため、モデルの学習完了後に起こった出来事や、株価・ニュース・法律の改正などの頻繁に更新される情報については古い情報、もしくは全く知らない状態です。
こうしたLLMの課題を、RAGは解決できます。応答の生成前に、外部の知識ソースを検索し、最新の状態に保つことで、常にリアルタイムの情報に基づいた回答を提供できるのです。
たとえば、昨日発表されたばかりの新しい業界規制について質問されても、関連する最新文書をRAGが検索できれば、LLMはそれに基づいて正確な情報を提供できます。
しかし、ドキュメント検索やDB検索のRAGのリアルタイム性は、検索対象が最新の状態にアップデートされている前提があってこそ担保されます。そのため、リアルタイム性を求める場合は、メンテナンスをこまめに行うようにしましょう。
機密情報の漏えいリスク軽減
企業データをLLMで活用する際の懸念点は、機密情報や個人情報の漏洩リスクです。RAGは、こうしたリスクを管理するための有効なアプローチとなる可能性があります。
たとえば、LLMに機密情報を含む大量のデータを直接学習させる方法(ファインチューニングなど)では、モデル内部に情報が記憶され、意図しない形で外部に漏れる危険性があります。
一方で、RAGでは機密情報はLLM本体とは分離された知識ベースに保管されます。LLMは応答時に必要な情報だけを検索して参照する形となり、モデル自体に機密情報が埋め込まれるわけではありません。
さらに、RAGはユーザーの役職や所属部署などの属性に基づいて、アクセスできる情報の範囲を制御する「アクセス制御」を実装しやすい利点もあります。これにより、権限のないユーザーが、機密情報を含んだ応答を受け取ることを防ぐことが可能です。
しかし、知識ベース自体のセキュリティ確保や厳格なアクセス制御ルールの設定・運用は不可欠である点に注意しましょう。
学習データの維持・管理コストの削減
LLMがアクセスできる知識を常に最新の状態に保つためには、知識の更新作業が必要です。方法のひとつにファインチューニングがありますが、多大なコストと時間を要する点が課題です。
新しい情報でモデルを再トレーニングするには、高品質な学習データセットの準備や、高性能なコンピューターリソースが必要になります。こうした知識更新に関わるコストと手間を、RAGによって削減できる可能性があります。
RAGの知識本体は、外部データベースや文書ファイルに存在します。そのため、知識を更新したい場合は、基本的にはこの外部データソースを修正・追加し、検索用のインデックスを更新するだけで済むのです。
LLM自体を再トレーニングする必要がないため、情報が頻繁に変わるようなドメインでは、ファインチューニングを繰り返すよりもコスト効率が良くなる可能性があります。
ただし、RAGにもデータベース運用などのコストは発生するため、総合的な評価は必要です。
RAGの構築プロセス
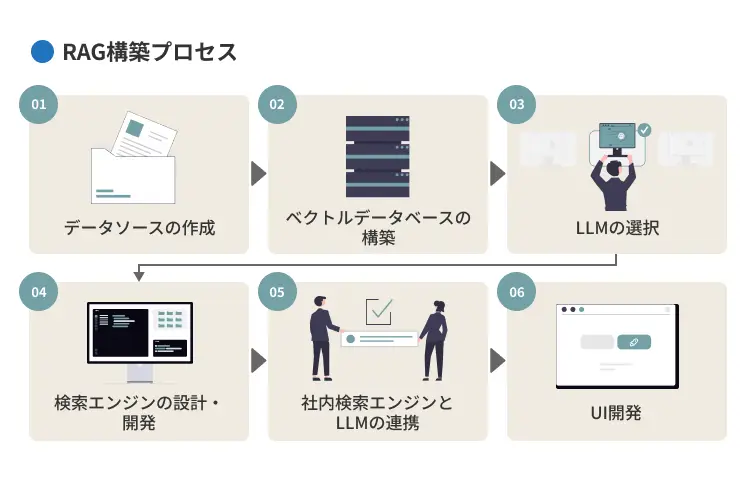
RAGシステムは複数の要素から成り立っており、それぞれの段階を順に進めることで、効果的にシステムを構築できます。具体的なプロセスは、以下のとおりです。
- データソースの作成
- ベクトルデータベースの構築
- LLMの選択
- 検索エンジンの設計・開発
- 社内検索エンジンとLLMの連携
- UI(ユーザー・インターフェース)開発
1.データソースの作成
RAGシステムの構築における最初のステップは、AIが参照するデータソースの準備です。RAGの応答品質を左右する土台となるため、丁寧に進める必要があります。
データソース準備の工程は、以下のとおりです。
- システムに活用したい情報源を特定:
社内マニュアル・FAQ・製品カタログ・過去のレポート・データベースなど - クリーニング作業:
情報源からテキストデータを抽出し、不要な情報(HTMLタグや定型文など)を取り除く - 文書の分割:
長い文書をLLMが扱いやすい、かつ意味のある単位に分割する(分割方法には文字数で区切る方法や、文・段落構造を利用する方法などがある) - 各分割単位にメタデータを付与:
出典・作成日・キーワードなどを付与することで、後の検索精度を高めるのに役立つ
これらデータ準備が、RAGの性能を最大限に引き出すための鍵となります。
2.ベクトルデータベースの構築
次に、ベクトル検索やセマンティック検索などを可能にするためのベクトルデータベースを構築します。構築手順は、以下のとおりです。
- 埋め込みモデルを使って数値ベクトルに変換
- 生成されたベクトルと元データを、ベクトルデータベースに格納
- インデックス(ベクトル同士の類似度を効率よく比較できる検索用の仕組み)を作成
まず、準備した文書を「埋め込みモデル」を使って数値ベクトル(埋め込みベクトル)に変換します。このベクトルが、テキストの意味を数値的に表現したものになります。
次に、生成されたベクトルとそれに対応する元のテキスト情報(分割単位)や付随するメタデータを、ベクトルデータベースに格納します。
ベクトルデータベースは、大量のベクトルデータの中から、与えられた質問ベクトルと類似したベクトルを高速に探し出すことに特化したデータベースです。代表的なものに、以下が挙げられます。
- Pinecone
- Weaviate
- Milvus
- Chroma
- pgvector
- FAISS
- Qdrant など
データベース内部では、ベクトルが効率的に検索できるように「インデックス」が作成されます。これにより、ユーザーからの質問に対して、関連性の高い情報を迅速に見つけ出すことが可能です。
3.検索エンジンの設計・開発
ベクトルデータベースとLLMを選択したら、次はそれらを繋ぐ中核部分となるRAGにおける検索エンジン(リトリーバー)の設計・開発です。
検索エンジンは、ユーザーの質問を受け取り、ベクトルデータベースを検索し、LLMに渡す関連性の高い情報を効率的に取得する役割を担います。
基本的な処理としては、ユーザーの質問をベクトルに変換してデータベース内の情報と意味的な類似度を比較し、スコアが高い上位K件の情報単位(例:段落や節など)を取得します。
より高い精度を目指したい場合は、キーワード検索とベクトル検索の結果を組み合わせる「ハイブリッド検索」の実装や、取得した情報に付与されたメタデータを使って結果を絞り込む「フィルタリング」機能の追加が有効です。
また、初期検索で得られた候補リストを、より精度の高いモデルに並べ替える「リランキング」処理を導入することも、応答品質の向上に繋がります。これらの検索ロジックは、LangChainやLlamaIndexなどのフレームワークを利用することで、開発を効率化できます。
4.LLMの選択
RAGシステムにおいて、最終的な回答を生成する役割を担うのがLLMです。どのLLMを選択するかが、システムの応答品質や特性を決定する重要な要素になります。
たとえば、以下のようなLLMが主流です。
- OpenAI|GPTシリーズ
- Anthropic|Claudeシリーズ
- Google|Geminiシリーズ
- Meta|Llamaシリーズ
選定にあたっては、いくつかの観点から比較検討が必要です。たとえば、以下を比較しながら検討すると良いでしょう。
- 性能:生成される文章の自然さや正確性、指示に従う能力
- コンテキストウィンドウサイズ(一度に処理できるトークン数):質問文と検索結果のインプットに関わる
- レイテンシ(応答速度):作業効率に関わる
- 利用コスト:API料金や運用費など
- 特定のタスクへの適性:要約・対話など
また、機密情報を扱う場合には、外部APIを利用するか、自社環境でモデルを運用するかといったセキュリティ面での判断も必要になります。
5.社内検索エンジンとLLMの連携
検索エンジン部分が設計・開発できたら、次はその検索エンジンと選択したLLMを連携させ、RAGシステム全体のワークフローを完成させます。この連携は、RAGシステムがスムーズに動作するための重要なステップです。
具体的には、ユーザーからの質問を起点として、以下のような一連の流れを制御する仕組みを構築します。
- 質問を検索エンジンに渡し、関連情報を取得
- 取得した情報(コンテキスト)と元の質問を組み合わせてLLMへの指示(プロンプト)を作成
- 作成したプロンプトをLLMに送信し、回答を生成
- 生成された回答をユーザーに返す
また、これらプロセス管理には、以下のような「オーケストレーション・フレームワーク」が役立ちます。
- LangChain
- LlamaIndex
- Semantic Kernel
これらのフレームワークは、各コンポーネント間のデータの受け渡し、API呼び出しの管理・プロンプトの動的な組み立て、会話履歴の管理といった複雑な処理を容易にする機能を提供します。
連携部分では、各ステップでのエラー(検索失敗、APIタイムアウトなど)を適切に処理するエラーハンドリングも重要になるでしょう。
6.UI(ユーザー・インターフェース)開発
RAGシステムのバックエンド(データ処理やAI連携部分)が完成したら、最後のステップとして、ユーザーがシステムと対話するための「ユーザーインターフェース(UI)」を開発します。
UIは、ユーザーがシステムの機能を利用するための窓口であり、その使いやすさがシステム全体の評価や利用率に大きく影響します。一般的なUIは、ユーザーがテキストで質問を入力し、システムからの回答がチャット形式で表示されるものです。
UIを設計する際には、「誰が」「どのような目的で」利用するかを考慮することが重要です。たとえば、回答の信頼性を高めるために、AIが生成した回答と一緒に、根拠となった情報源を表示する機能は有効です。
また、普段から利用している社内ツール(Slack・Microsoft Teams・社内ポータルなど)にRAGを活用したLLMを連携することで、より自然な形でシステムを利用できるようになります。
応答が表示されるまでの待ち時間を示すインジケーターや、エラー発生時の分かりやすいメッセージ表示なども、快適に利用するためにも考慮しましょう。
RAGの実装方法
RAGの導入を検討する際、自社の技術力や予算、求める機能に応じて最適な方法を選択することが重要です。
本章では、以下の代表的な3つの実装アプローチについて解説します。
- ツールキットを用いたPython実装
- クラウドサービスによる実装
- ローカル環境での実装
ツールキットを用いたPython実装
RAGシステムを構築する際、Pythonのライブラリやフレームワークを利用する方法は、非常に一般的で柔軟性の高いアプローチです。主要なツールキットに、「LangChain」や「LlamaIndex」などが広く活用されています。
これらのツールキットは、以下のようなRAGに欠かせない機能を提供します。
- 文書データの読み込み
- テキストの分割
- 意味ベクトルへの変換(埋め込み)
- ベクトルデータベースへの格納と検索
- LLMとの連携
- 再利用可能な部品(コンポーネント) など
使用するLLMや埋め込みモデル、ベクトルデータベースなどを自由に選択・組み合わせるなど、特定の要件に合わせた細かなカスタマイズが可能な点も、ツールキットの大きなメリットです。
一方で、Pythonやツールキットに関する知識が必要になり、インフラの構築や管理も自社で行う必要がある点に注意しましょう。
クラウドサービスによる実装
AWS(Amazon Web Services)やMicrosoft Azure、GCP(Google Cloud Platform)といった主要なクラウドプラットフォームが提供するマネージドサービスを活用し、RAGを実装する方法も有力な選択肢です。
これらのクラウドベンダーは、RAGシステムの構築と運用を容易にするための様々なサービスを提供しています。たとえば、以下のようなサービスがあります。
- ベクトル検索機能を備えたデータベースサービス:Amazon OpenSearch Service・Azure AI Search・ Vertex AI Vector Searchなど
- LLMを利用するためのAPIサービス:Amazon Bedrock・Azure OpenAI Service・ GCP Vertex AIなど
- RAG専用のマネージドサービス:Amazon Bedrock Knowledge Basesなど
これらのサービスを利用するメリットは、サーバーの構築や管理といったインフラ運用の手間が大幅に削減される点、そして需要に応じて容易にシステムを拡張(スケール)できる点です。
一方で、提供される機能や選択できるコンポーネントがクラウドベンダーの枠内に限定されるため、カスタマイズの自由度はやや低くなる傾向があり、特定のベンダーへの依存度が高まる可能性に考慮する必要があります。
ローカル環境での実装
企業の機密情報など、外部にデータを持ち出すことが難しい場合に、自身のPCや社内サーバーといったローカル環境でRAGシステムを構築・実行する方法があります。
ローカル環境から実装する利点は、データセキュリティとプライバシーを最大限に確保できることです。全てのデータ処理が自身の管理下にある環境内で完結するため、情報漏洩のリスクを最小限に抑えられます。
実装には、オープンソースのツールを組み合わせることが一般的です。これらのローカルコンポーネントを、Pythonツールキット(LangChain・LlamaIndexなど)に連携させることでローカルRAGを実現できます。
ただし、高性能なLLMをローカルで快適に動作させるためには、相応のマシンスペック(とくにGPUや大容量メモリ)が必要となる点と、クラウドサービス利用時と比べてセットアップや運用管理が複雑になる点には注意が必要です。
RAGの応用例
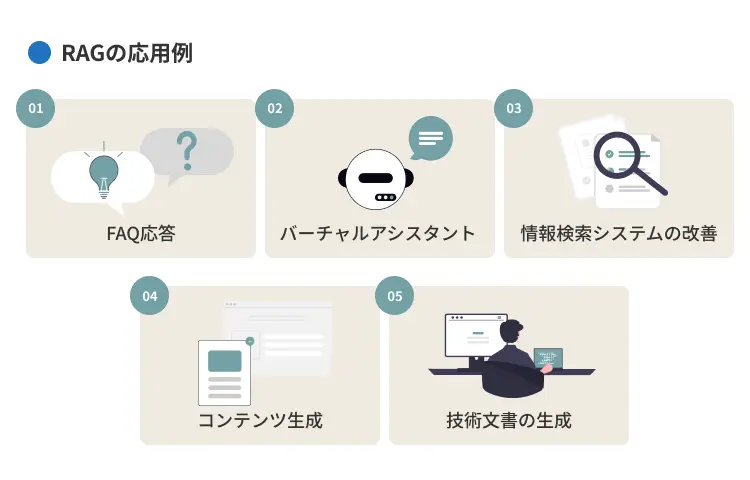
RAGはLLMの能力を拡張し、様々な業務の効率化や品質向上に貢献します。
本章では、RAG(検索拡張生成)が実際のビジネスシーンでどのように活用されているかを紹介します。具体的な応用例は、以下のとおりです。
- FAQ応答:よくある質問への自動回答精度向上
- バーチャルアシスタント:パーソナライズされた高度な対話支援
- 情報検索システムの改善:社内情報などへのアクセス効率化
- コンテンツ生成:事実に基づいた文書作成の支援
- 技術文書の生成:専門文書の作成・検索効率化
FAQ応答
RAG技術は、顧客や社内からの「よくある質問(FAQ)」に対応するシステムの能力を大幅に向上させます。
従来のFAQシステムは、あらかじめ登録された質問と回答の組み合わせや、単純なキーワード検索に依存することが多く、ユーザーが求める回答を的確に提示できません。
一方で、RAGはユーザーが自然な言葉で入力した質問の意図を理解します。そのため、関連するFAQ文書やマニュアル、ナレッジベース記事からもっとも適切な情報を検索できます。
これにより、従来よりも幅広い質問にも対応でき、回答精度の向上が期待できます。また、RAGによるFAQ応答システムは24時間対応可能なため、顧客満足度の向上やサポート担当者の負担軽減にも繋がるでしょう。
バーチャルアシスタント
RAGは、単純な質疑応答を行うチャットボットを超えた、より高度な機能を持つ「バーチャルアシスタント」の実現を可能にします。
一般的なバーチャルアシスタントは、自身の持つ限られた知識や機能の範囲内でしか動作できない一方で、RAGを組み込むことで以下のような機能が可能になります。
- CRM(顧客関係管理)システムから特定の顧客情報を取得
- 最新の市場データを参照
- ユーザー個人のスケジュール情報を確認 など
また、以下のようなパーソナライズされた情報の提供や、複雑なタスク支援も実現可能です。
- 顧客の過去の購入履歴を基にした製品の推薦
- リアルタイムの経済指標を反映した情報の提供
- 過去のサポート事例を参照した具体的な問題解決の支援
実際の導入事例として、Intercom社はカスタマーサポート向けのAIエージェント「Fin」にAnthropicのClaudeを活用し、問い合わせに対してナレッジベースから情報を抽出し応答を生成しています。この仕組みにより、初期導入段階で平均51%、最適化後には最大86%という高い自動解決率を実現しました。FAQの自動応答や問い合わせ対応の迅速化により、サポート品質と効率の両立を図っています。
情報検索システムの改善
企業では、社内規定やマニュアル、過去のプロジェクト資料など、膨大な情報が蓄積されています。こうした必情報を探し出すのに時間がかかるという課題を、RAGの情報検索システムを改善することで解決につなげられます。
従来のキーワード検索では、関連しそうな文書がリストアップされるだけで、ユーザーはそこから目的の情報を見つけ出す必要がありました。
一方で、RAGを導入したシステムでは、ユーザーが自然言語で質問するだけで意図を理解し、関連文書の検索やLLMが文書内容を解釈・要約した直接的な回答を生成します。
たとえば、「出張時の日当について教えて」と質問した際に、関連の規定文書を探し出す手間をなくしつつ、内容を要約した上で提示されます。
コンテンツ生成
RAGは、ブログ記事やレポート、マーケティング資料やメール文面といった様々なコンテンツ生成の品質と効率を高めることもできます。LLMは文章を作成する能力に優れていますが、その内容が常に正確であるとは限りません。また、最新の情報を反映しているとも限りません。
RAGは、コンテンツを生成する前に、テーマに関連する信頼できる外部情報源を検索し、得られた事実・情報を基盤としてLLMにコンテンツを作成させます。これにより、生成されるコンテンツの正確性・信頼性・最新性を大幅に向上させられるのです。
たとえば、市場動向に関するレポートを作成する場合、RAGが最新の市場調査データを検索・参照することで、データに基づいた説得力のあるレポートを効率的に作成できます。商品データに基づいて、説明文を生成することで売上貢献にもつなげられるでしょう。
また、LANYでは、人間とAIの共創により、最高品質の記事をスピーディーにご提供するLANY式 SEO記事制作代行サービスを提供しています。ご興味をお持ちの方は詳細ページからサービス内容をご覧ください。
LANY式 SEO記事制作代行サービス概要ページはこちら>>
技術文書の生成
マニュアルや仕様書、APIドキュメントや研究論文など、専門性が高く正確性が厳しく求められる技術文書の生成においても、RAGは非常に有効です。
これらの文書は、しばしば複雑な情報や専門用語を多く含み、作成・理解に時間と専門知識が必要です。RAGは、既存の技術文書やデータベース、ソースコードや研究論文リポジトリなどを知識ソースとして、必要な情報を正確に検索・抽出する能力を提供できます。
たとえば、新しいソフトウェアの機能に関するドキュメントを作成する際に、関連する設計書やコードコメントをRAGが参照し、基本的な説明や仕様の草稿を自動生成するといった支援が可能です。
また、エンジニアが特定の技術仕様について質問した際に、RAGが過去の実験データや技術レポートから該当箇所をピンポイントで検索し、要点をまとめて提示することもできます。
【項目別】RAGの最適化方法
RAGは、システムを一度構築したら終わりではなく、継続的に評価し改善していくことが重要です。本章では、以下の3つの最適化方法について解説します。
- 検索品質の改善
- 生成AI品質の改善
- 効果測定・分析
検索品質の改善
RAGシステムの応答精度を高める上で、「検索品質」の改善はもっとも重要な要素です。なぜなら、LLMが参照する情報(検索結果)の質が低ければ、的確な回答を生成することはできないからです。
RAGによる検索品質を改善するための方法には、主に以下が挙げられます。
- 文書の分割方法の最適化:
文書の種類や検索したい情報の粒度に合わせて、分割単位のサイズや分割方法(意味的な区切りを考慮するなど)を調整 - 「埋め込みモデル」の選定と最適化:
データの内容や言語に適した高性能なモデルを選び、場合によっては自社データでファインチューニングすることも有効 - 「検索アルゴリズム」の工夫:
ベクトル検索とキーワード検索を組み合わせた「ハイブリッド検索」や、初期検索結果を絞り込む「リランキング」、クエリそのものを検索に適した形に書き換える「クエリリライティング」も有効 - 前処理・正規化の工夫:
埋め込み処理の前に、テキストの正規化や不要語の除去、表記ゆれの統一といっ*前処理(プレプロセッシング)を行うことで、Embeddingの一貫性と精度を高める
これらの改善策を試し、評価を通じて最適な組み合わせを見つけましょう。
生成AI品質の改善
検索品質を高めることと並行して、LLM(生成AI)が検索結果を適切に利用し、高品質な応答を生成できるように「生成品質」を改善することも重要です。
検索結果が良くても、LLMがそれを無視したり、誤って解釈したり、あるいは検索結果にない情報を付け加えてしまい、ハルシネーションを起こしてしまう可能性があります。
生成品質を改善するための主な方法は、「プロンプトエンジニアリング」です。たとえば、以下のように、LLMに対する指示(プロンプト)を明確にしましょう。
- 提供された情報のみに基づいて回答すること
- 情報源を明記すること
- 不明な場合は『不明』と回答すること など
検索結果の活用方法そのものを設計する「コンテキスト注入」も重要です。これは、検索によって取得した情報だけでなく、ユーザーの状況や業務ロジックなど、回答に必要な文脈(コンテキスト)を事前にプロンプト内に組み込む方法です。
プロンプト例
| コンテキスト - 返品ポリシー:購入後30日以内に限り可 - 送料:無料(国内のみ) 参考情報: [ユーザーの購入履歴] 質問:この商品は返品できますか? |
また、指示追従能力が高く、ハルシネーションを起こしにくいとされるモデルを選ぶ、あるいは特定のタスクに合わせてLLMを「ファインチューニング」することも有効でしょう。
さらに、生成された回答をユーザーに提示する前に、事実確認や不適切表現のチェックを行う「ガードレール」を設けることも、応答の信頼性を高める上で効果的です。
以下の記事では、LLM(大規模言語モデル)と生成AIの仕組みや違い、活用例、課題について具体的に解説しています。こちらもぜひ参考にしてみてください。
あわせて読みたい

効果測定・分析
RAGシステムの最適化を進める上で、行った改善策が実際に効果を発揮しているかを客観的に測定・分析するプロセスも不可欠です。
RAGシステムの評価では、主に「検索」と「生成」の2つの側面から性能を測ります。具体的には、以下のとおりです。
| 検索品質 | 検索結果の関連性を示す「Context Precision」や、必要な情報が網羅されているかを示す「Context Recall」といった指標を用いる。 |
|---|---|
| 生成品質 | 回答が検索結果に忠実かを示す「Faithfulness」や、回答が質問の意図に合っているかを示す「Answer Relevancy」などが重要。 |
これらの指標を効率的に測定するために、「Ragas」などの評価フレームワークの活用が推奨されます。
定期的にこれらの指標を測定・分析し、具体的な問題点を特定することで的確な改善策が提案され、生成AIの品質向上につなげられます。
RAG運用における注意点
本章では、RAG構築による効果を維持し、安定運用していく上での注意点について解説します。運用フェーズで重要となるポイントは、以下のとおりです。
- 最適なデータソース選定
- 効果判断基準の策定
- LLM統合時の課題
- 機密情報の取り扱い
- 継続的なメンテナンス
最適なデータソース選定
RAGの応答品質は、参照するデータソースの質に大きく左右されます。そのため、システム運用を開始した後も、データソースが最適であり続けているかを継続的に評価し、見直すことが重要です。
データソースを評価する際は、以下を基準にしましょう。
- 正確性:情報が事実として正しいか
- 最新性:情報は古くなっていないか、更新頻度は十分か
- 網羅性:必要な情報範囲をカバーできているか
- 関連性:ユーザーが求める回答に関係があるか
これらに基づいて定期的にデータソースを見直し、不要な情報の削除や新しい情報の追加を行うデータガバナンスを確立することが、RAGの信頼性を維持する上で不可欠です。
効果判断基準の策定
RAGシステムを運用する上で、そのシステムが本当に役立っているのか、期待通りの効果を発揮しているのかを客観的に判断するための基準を明確に定めておくことも重要です。
この基準がないと、システムの改善活動が的外れになったり、導入効果を説明できなかったりする可能性があります。効果を判断する基準は、大きく分けて2種類あります。
一つは、システムの技術的な性能を示す指標です。たとえば、以下のような要素が含まれます。
- 検索結果がどれだけ質問に関連していたか(Context Precision)
- 必要な情報をどれだけ網羅的に検索できたか(Context Recall)
- 生成された回答が検索結果に忠実か(Faithfulness)
- 回答が質問に適切か(Answer Relevancy) など
もう一つは、ビジネス上の成果を示す指標(KPI)です。これはシステムの導入目的によって異なります。たとえば、以下が挙げられます。
- 問い合わせ対応時間の削減率
- 顧客満足度(CSAT)の向上率
- 従業員の生産性向上率
- 特定のタスク完了率 など
LLM統合時の課題
RAGシステムの中核を担うLLMとの連携部分は、システムの安定性や品質に影響を与える可能性のある、運用上の注意点も含んでいます。
たとえば、外部のLLM APIを利用している場合、APIの利用制限(レート制限)に達してしまう可能性があります。システム利用が集中する時間帯には、応答遅延やエラーの原因にもなるでしょう。
また、検索結果が多い場合は、LLMに渡す情報を絞り込む必要があり、その過程で重要な情報が失われてしまう可能性も考えられます。
加えて、プロンプトで指示をした際にLLMが検索結果を無視して回答したり、ハルシネーションを起こすなど、振る舞いを完全に制御することは難しいのが現状です。
したがって、これらの課題に対処するためには、以下のような工夫が求められます。
- APIの利用状況を監視し必要に応じてプランを見直す
- LLMに渡すコンテキスト情報を最適化(要約やフィルタリング)
- プロンプトを継続的に改善
- エラー発生時の処理を適切に設計
機密情報の取り扱い
RAGシステムで社内文書や顧客データといった機密性の高い情報を扱う場合において、セキュリティとプライバシーの確保は運用における最重要課題です。
情報漏洩は企業の信頼を著しく損ない、法的な問題にも発展しかねません。運用段階では、まずアクセス制御の徹底が求められます。従業員の入退社や異動に伴う権限変更をシステムに速やかに反映し、各ユーザーが必要最小限の情報にのみアクセスできるようにしましょう。
知識ベースに追加されるデータについても、個人情報や機密情報が含まれていないか、含まれている場合はマスキングや匿名化などの適切な処理が施されているかを継続的にチェックするプロセスが必要です。
また、誰がいつどの情報にアクセスしたかを記録する「監査ログ」を定期的に監視し、不審な動きがないかを確認することも重要です。
悪意のある入力によって情報が不正に引き出されるリスクにも備え、入力・出力のフィルタリング機能の有効性を継続的に評価・改善しましょう。
継続的なメンテナンス
RAGシステムは、一度構築したら終わりというわけにはいきません。性能や価値を長期的に維持・向上させるためには、継続的なメンテナンスが不可欠です。
メンテナンスの対象は多岐にわたり、もっとも重要なのは知識ベースの鮮度維持です。参照する情報ソースは日々変化・増加していくため、定期的に新しい情報を取り込み、古い情報を更新・削除し、検索用インデックスを再構築するプロセスが必要になります。
次に、パフォーマンスの監視とチューニングがあります。応答速度やコスト、設定した効果測定指標を継続的に監視し、性能低下が見られた場合には検索アルゴリズムのパラメータ調整やLLMに渡すプロンプトを修正します。
また、システムを構成するLLMやベクトルデータベース、フレームワーク自体も進化していくため、必要に応じてコンポーネントをアップデートすることも考慮すべきです。ユーザーからフィードバックを収集するなどし、全体を改善できる仕組みを構築しましょう。
まとめ
RAGはLLMの知識を拡張する有効な手法です。自社データを活用し、精度の高い回答を得るには、適切な実装プロセスが不可欠になります。まずはデータ準備から始め、関連情報を効率的に検索できる仕組みを構築しましょう。
また、RAGは社内ナレッジ活用やカスタマーサポート、コンテンツ生成など様々な業務で効果を発揮します。適切に導入し、業務効率化や競争優位性の確保につなげましょう。
なお、LANYでは、「未来の顧客接点を作る、LLM最適化」をご支援するLLMOコンサルティングサービスをご提供しています。
|
などをお悩みの方は、ぜひご活用ください。
LANY LLMOコンサルティングサービス概要資料のダウンロードはこちら>>
以下のような無料お役立ち資料もご用意してますので、ご参考ください。
※本記事の制作には生成AIを活用していますが、編集者によってファクトチェックや編集をしています。また、掲載している画像はすべてデザイナーが制作したものです。
「強いLLMO」出版!
LANY代表・竹内の3冊目の書籍『強いLLMO』が2025年9月26日に発売開始しました!
AIに普及により消費者行動が大きく変わってきた今、
- マーケティング投資の前提をどうアップデートすべきか
- 組織として新たに備えるべき指標・スキル・体制は何か
といった経営視点の問いにも応える内容となっているため、AI時代のブランド戦略に悩む経営者・マーケティング責任者必読の一冊となっております。ぜひ手にとってみてください。
竹内のnote▶︎LANYがLLMOに舵を切る理由
【無料お役立ち資料】 LLMO白書

AI検索時代に「自社ブランドが選ばれる状態」を再現性高く作るためのマーケティング戦略と具体戦術を、全70ページにわたるボリュームでまとめたLLMO(AI検索対策)の必携資料です。
ここ数年でユーザーの検索体験は「リンクをクリックしてサイトを訪問する」ものから「AIから答えを直接もらう」ものへと激変しました。この変化により、従来の流入を重視するSEOだけでは、顧客の意思決定に関与し続けることが困難になりつつあるため、AIに直接選ばれる必要性が高まっています。
本資料では、実際に検証から導き出した「AI検索の勝ち筋」を、実証データや明日から使えるフレームワークとともに解説しています。
\マーケターのあなたへ/
デジタルマーケティングの課題解決に役立つ情報をお届けする
購読者数4,200人超えの人気メルマガ
☑️ 最新の業界情報をキャッチアップできる
☑️ 施策の成功事例や限定Tipsが届く
☑️ 限定ウェビナーの情報がいち早く届く
初心者マーケターから
マーケの最新情報をキャッチアップしたい経営者の方まで
役立つ内容のためぜひご登録ください!
関連記事






デジタルマーケティングのお悩み、
まずはお気軽にご相談ください。
サービス詳細は資料でもご確認いただけます。