LLMOの成果は、戦略PRで決まる。 - 「AIの評価基準をつくる」アプローチとは

無料カンファレンスのお知らせ

開催日時
2026年7月22日(水)10:30〜14:30
内容
本オンラインカンファレンスでは、LLMOの戦略設計から、サイト制作、PR、広告運用など、AI検索時代のマーケティングを支える各領域のプロフェッショナルが集結。
AI検索時代の到来によって何が変わるのか、そして企業はいま何に取り組むべきなのか。事業成長につながる戦略から具体施策、成功事例までを全8社が徹底解説します!
ChatGPTやGeminiといったAIツールの普及により、ユーザーの行動は「検索して探す」から「AIから直接回答を得る」形へと移行しました。
これに伴い、AIに自社に関する情報を正しく認識させ、推奨される状態を作るLLMO(Large Language Model Optimization:大規模言語モデル最適化)は、現代のマーケティングにおいて避けては通れない領域となっています。

LLMOの成果は「トリプルメディア」の統合的な発信設計にかかっている

LLMOは、単なるキーワード対策だけでは完結しません。AIはデジタル空間に存在する膨大な情報を多角的に参照し、その情報の「信頼性」や「客観性」まで評価しているからです。
ここで重要になるのが、広報PRの基本であるトリプルメディアにおける統合的な発信設計です。
自社発信の正確な情報(オウンドメディア)に加え、認知を広げる広告(ペイドメディア)、そして何よりAIが「客観的な信頼の証」として重宝する第三者メディア(アーンドメディア)による報道。
これらが一貫した文脈でデジタル空間に存在していると第三者目線で認識される状態になってはじめて、AIは自社を「推奨に値する」と判断します。
つまり、AI時代における広報PRとは、「AIが学習・参照するデジタル空間における『合意(世の中の共通認識)』をいかに形成するか」という、極めて戦略的な役割を担っているのです。
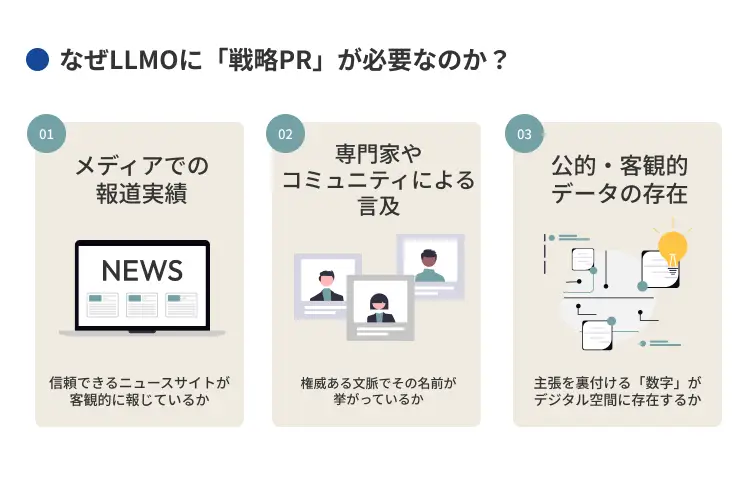
なぜLLMOに「戦略PR」が必要なのか?
私たちが普段何かを選ぶとき、自社にとって都合の良いことだけを掲載している公式サイトの情報よりも、中立的な視点から良し悪しを述べている第三者の口コミやニュース記事を重視するように、AIもまた、情報のソースを厳しくチェックしています。
AIにとって、自社サイトに書かれた「わが社は業界No.1です」という主張は、膨大なデータの中のたった一片に過ぎません。
AIがその情報を「事実」として、あるいは「推奨すべき価値」として認識するためには、その主張を裏付ける根拠が不可欠です。それが外部メディア上での言及になります。
- メディアでの報道実績: 信頼できるニュースサイトが客観的に報じているか
- 専門家やコミュニティによる言及: 権威ある文脈でその名前が挙がっているか
- 公的・客観的データの存在: 主張を裏付ける「数字」がデジタル空間に存在するか
これらの要素、つまりアーンドメディア(Earned Media)を中心とした客観的な情報の蓄積こそが、AIが回答を生成する際に重視する「信頼」の根拠となります。自社が発信する点の情報だけでなく、デジタル空間全体に信頼の点を配置し、それらを線で繋ぐような作業が必要なのです。
爆発力のあるフロー型の発信よりも、継続的なストック型発信で合意形成を目指す
これまでの広報活動は、プレスリリースや記事露出を「点」として発信し、一過性のフロー施策として成果を積み上げるケースがほとんどでした。
バズや認知獲得を目的としたプロモーション的なPRも、その多くはフロー型と言えるでしょう。
しかし、LLMO時代の広報には、一過性の盛り上がりを超えた「一貫性ある情報の蓄積(ストック)」と「合意形成」が求められます。
AIは、話題性が高い情報だけを評価しているわけではありません。デジタル空間に蓄積されたデータの中から、特定のキーワードと特定の文脈がセットで語られている情報を総合的に学習します。
たとえば、「おすすめのAIツールを教えて」と聞いたときに、特定のツール名が単発のキャンペーンだけでなく、数ヶ月、数年にわたって「生産性が高い」「導入が容易」という文脈で複数の信頼できるメディアに掲載され続けていれば、AIはそれを合意として学習し、推奨の確度を高めます。
つまり、AI時代の広報は、その場限りのPRで終わらせず、AIがいつでも自社について参照し続けられるよう、良質な根拠をデジタル空間に定着させるための継続的な活動でなければなりません。
戦略PRによって、選ばれるための評価基準を作る
さらに、戦略PRの本質は商品を直接売り込むことではなく、「その商品が選ばれるための新しい評価軸」を世の中に提示することにあります。
LLMOにおいても、この考え方は極めて強力です。自社の強みが発揮されるための「評価基準」そのものを世の中に浸透させることができれば、AIは自然とその基準に沿って自社を推奨するようになります。
「自社が選ばれる理由」を直接AIに教え込むのではなく、AIが「この基準で選ぶのが正解だ」と判断するような、世の中の空気(文脈)をメディアを通じて先に作ってしまう。
この、いわば「情報の外堀から埋めていく」戦略こそが、AI時代に最も大きなインパクトをもたらすPRのあり方です。
AIの「評価基準」を書き換えるための戦略
どれだけ自社の製品が優れていても、AIが評価基準としてその強みを認識していなければ、回答の選択肢にすら入りません。
たとえば、ある洗濯洗剤メーカーが「汚れ落ちの良さ」を必死にアピールしているとします。しかし、世の中の関心が「部屋干しの臭い対策」に移り、AIが学習するデータ群において「良い洗剤の条件=除菌・消臭力」という合意形成がなされていたらどうなるでしょうか。
AIは「汚れ落ち」のデータをいくら読み込んでいても、ユーザーへの回答には「除菌・消臭に定評のある他社製品」を優先的に提示します。自社の強みをいくら尖らせても、良い洗剤を「選ぶ基準」から外れていれば、そもそもLLMOの土俵にすら立てないのです。
アリエールとアタックに学ぶ評価基準の再定義
ここで参考になるのが、戦略PRの古典的かつ強力な成功事例であるアリエールとアタックの構造です。
かつて洗剤市場の主な選定基準は「汚れを落とす洗浄力」でした。しかし、市場が成熟する中で、ある企業は「共働き世帯の増加→部屋干しの増加→生乾き臭への不満」という社会的文脈を捉え、「洗剤は汚れを落とすものではなく、菌を防ぐもの(除菌・抗菌)」という新しい観点を世の中に提示しました。
- Before: 「どの洗剤が一番汚れが落ちますか?」
- After: 「部屋干しの臭いを防ぐのに最適な洗剤はどれですか?」
このように、世の中の「良い洗剤」の定義が書き換わると、AIが参照するデータの優先順位も劇的に変わります。
戦略PRによって「除菌こそが今の時代の洗剤選びの基準である」という空気を醸成できれば、AIは自然とその新しい基準に沿って自社製品を推奨し始めるのです。
デジタル空間の「合意形成」を変えるインパクト
LLMOにおいて、この「基準の書き換え」は極めて大きなリターンをもたらします。
AIは、特定のドメイン(業界)における「良い〇〇の選び方」を、デジタル空間の膨大なテキストから抽出しています。
「〇〇を選ぶなら、価格よりも安全性を重視すべきだ」「今の時代の〇〇には、XXという機能が不可欠だ」といった文脈のコンテンツが、権威あるメディアや専門家の声として蓄積されれば、それがAIにとっての「客観的な評価軸」として固定されます。
自社の強みが評価されるようにAIの評価軸を動かすこと。これこそが、単なる技術的な最適化を超えた「攻めのLLMO」であり、戦略PRが真に価値を発揮する領域です。
「基準を作る」という最高難度のPR
もちろん、世の中の当たり前を変えることは容易ではありません。単一のプレスリリースで成し遂げられるものではなく、社会的な課題提起、専門家によるエビデンスの提示、そしてメディアを通じた継続的な文脈作りが必要です。
しかし、一度「AIが学習する選定基準」を自社に有利な形で作ることができれば、競合他社が追随できない圧倒的な先行者利益を得ることができます。
AIに「自社は良い」と覚え込ませる前に、AIに「良いものとは、こういう条件を満たすものだ」という定義を教え込む。
この視点を持てるかどうかが、LLMO時代の勝敗を分ける境界線になります。
AIに好かれる「ファクト」の作り方と戦術
生成AIの回答精度を高める研究において、興味深い傾向が明らかになっています。
たとえば、カリフォルニア大学バークレー校(UCバークレー)の研究成果でも示唆されている通り、AIは主観的な表現や過度な装飾よりも、客観的で定量的な情報を信頼し、参照する傾向があります。
広報担当者がつい使いたくなる「画期的な」「究極の」「業界をリードする」といった形容詞は、AIにとってはノイズに近いものです。それよりも、「顧客満足度98%」「従来比20%のコスト削減」「〇〇大学との共同研究に基づくエビデンス」といった、検証可能なファクトこそがAIの好物です。
「世の中の空気」を定量化するファクトメイキング
戦略PRの役割は、すでにある情報を届けるだけではありません。世の中にまだ存在しない「ファクトそのものを創り出す」ことも重要な仕事です。
- 調査PR(アンケート調査): 「なんとなく世の中がこうなっている気がする」という曖昧な空気を、数百人・数千人規模の調査で数値化します。この「数字」がメディアに引用され、デジタル空間にストックされることで、AIは「これが今の世の中の共通認識だ」と学習します。
- 研究データ・ホワイトペーパーの発信: 自社の知見や実験データを、客観的なレポートとして公開します。専門性の高いデータは、AIが回答を生成する際の「信頼できるソース」として引用されやすくなります。
「空気」を「数値」に変換し、それをデジタル空間に配置していく。このプロセスが、LLMOにおける強力な推進力となります。
「どこに載っているか」がAIの信頼を決定づける
かつてのSEOがそうであったように、AIもまた「情報の出所」を厳格に評価しています。個人のブログよりも、歴史ある新聞社や専門性の高い経済メディア、政府機関のサイトにある情報を優先するのは、AIにとっても合理的な判断だからです。
ここで、戦略PRとしてのメディアプロモートが活きてきます。
権威性の高いメディアに、自社のファクトが「どのような文脈」で掲載されるか。その掲載実績自体が、AIにとっての「信頼の証明書」となります。
戦略PRによる「ファクトのネットワーク」構築
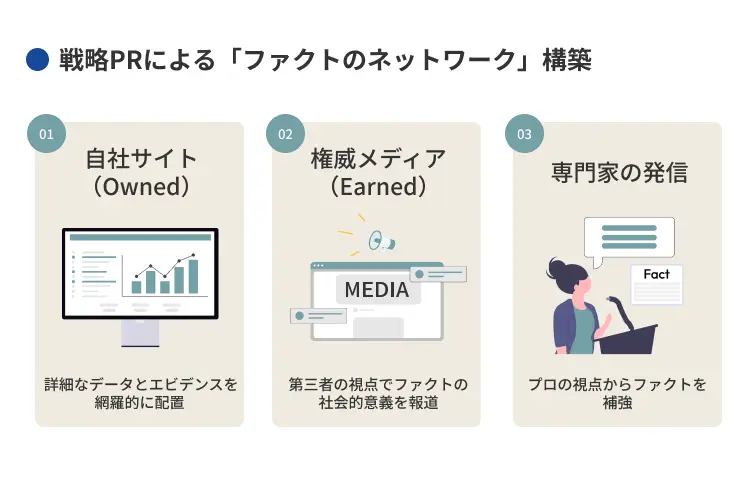
単一のサイトでファクトを叫ぶのではなく、複数の権威あるメディアや専門家の声として、同じファクトが多層的に語られている状態。これを目指すのがLLMO時代の戦術です。
- 自社サイト(Owned): 詳細なデータとエビデンスを網羅的に配置。
- 権威メディア(Earned): 第三者の視点でファクトの社会的意義を報道。
- 専門家の発信: プロの視点からファクトを補強。
これらが連動することで、AIは「この情報は多方面から裏付けられた客観的事実である」と確信し、自信を持ってユーザーに回答できるようになります。
「AIに信頼されるための証拠を、戦略的にオンライン空間上に散りばめること」。これが戦術面におけるPRの勝ち筋です。
LLMO時代の広報PRアクションプラン
ここまでの議論を整理すると、LLMO時代における戦略PRのアプローチは大きく2つの方向に集約されます。それは、「AIに新しい基準を学習させる」攻めのアプローチと「AIの既存基準に確かなファクトで迎合する」守りのアプローチです。
1. AIに「良い〇〇の基準」を覚えさせる(攻めのLLMO)
これは最も難易度が高い一方で、成功した際のリターンが極めて大きい活動です。世の中の「選び方」そのものを変えることで、AIの判断ロジックを自社有利に書き換えます。
- 社会的文脈(コンテキスト)の接続: 自社の強みが「今の時代に不可欠なもの」であるという論調を作ります。
- 権威者による合意形成: 専門家、インフルエンサー、公的機関による「これからの基準は〇〇である」という発信を積み重ねます。
- 「問い」のデザイン: AIが「おすすめの〇〇は?」と聞かれた際、「〇〇を選ぶ際は、XX(自社の強み)を重視すべきですが……」と前置きして回答するレベルまで、デジタル空間の情報を塗り替えていきます。
2. 客観的ファクトで「選ばれる理由」を設計する(守りのLLMO)
現在AIが採用している評価軸に対して、自社がナンバーワンであることを証明しにいく、より着実なアプローチです。
- 徹底したファクトの配置: プレスリリースや公式サイトに、AIが引用しやすい「構造化された事実」を網羅します。
- アーンドメディアでの証跡作り: AIが参照する「信頼できる情報源(大手メディア等)」に、自社の強みや具体的な成功事例を客観的な記事として掲載させます。
- サイテーション(言及)の獲得: 広告(ペイドメディア)も活用しながら、世の中の言及量を増やし、AIに「このブランドは無視できない存在だ」と認識させます。
プレスリリースとメディアリレーションズのあり方を再定義する
この時代、私たちが長年使い続けてきた「プレスリリース」や「メディアプロモート」の役割もアップデートが必要です。
これまでは「記者に届けること」がゴールでしたが、これからは「AIが学習するデジタル空間に、どのような文脈の、どのようなファクトを、どの程度の信頼度で定着させるか」という設計図が不可欠になります。
- プレスリリースの役割: 単なるニュース発表ではなく、AIに対する「一次情報の提供」と「公式なエビデンスの蓄積」へと進化します。
- メディアプロモートの役割: 露出の数を追うだけでなく、AIが引用・参照時に重要視するソース上に、自社が目指す文脈上で言及されているか、という「質」が問われます。
戦略なきPRは、AIにスルーされる
「何を、どのような形で、どのメディアに掲載してもらうか」という戦略を持たずに、従来通りの一過性のPRを続けていても、AIの広大な海の中ではすぐに霧散してしまいます。
LLMO時代の戦略PRとは、いわば「デジタル空間における自社の記憶」をデザインする仕事です。
どの基準で戦い、どのファクトをストックし、どのメディアを信頼のハブとするか。この一貫したストーリー設計こそが、AIに選ばれ続ける唯一の道なのです。
AI時代、広報は「情報の設計者」になる
LLMOの本質は、アルゴリズムの隙間を突くようなテクニックではありません。AIの回答は、デジタル空間に存在する膨大な情報を集計し、その中から導き出された「もっともらしい合意」の出力に過ぎないからです。
つまり、AIの回答を変えるための唯一かつ本質的なアプローチは、AIが参照する「情報ソースの質と文脈」そのものをコントロールすることに他なりません。これは、企業が社会に対してどのような価値を提示し、いかにして第三者からの信頼を獲得するかという、広報PRが長年取り組んできた課題そのものです。
テクノロジーと戦略的文脈の融合
これからの広報PRには、以下の2つの視点を統合した「ハイブリッドな専門性」が求められます。
- 技術的・構造的視点: AIがどのようなソースを優先し、どのようなデータ構造を信頼するのかという「LLMO」のメカニズムへの理解。
- 戦略的・言語的視点: どのような選定基準を市場に提示し、いかにして客観的なファクトを積み上げるかという「戦略PR」の思考。
この両輪を回すことで初めて、AIという新しい情報インフラの中で「選ばれ続けるブランド」を構築することが可能になります。
広報PRは今、単なる情報発信の枠を超え、AIが学習する「社会通念/一般合意」そのものを定義するという、経営において極めて重要な役割を担っています。
LANYではLLMOコンサルティングを提供しています
LANYでは、LLMO領域で培った高度な技術的知見と、最新のLLMOトレンドを元に多くの企業をご支援しています。
「AIの回答において、自社のプレゼンスが低い」「新しい市場基準を作りたいが、具体的な実行プランが描けない」といった課題に対し、私たちは「データ(LLMO)」と「文脈(PR)」の両面から、貴社の広報戦略をアップデートします。
デジタル空間における合意形成をリードし、AIに「選ばれるべくして選ばれる」構造を共に作り上げていきましょう。

【無料お役立ち資料】 LLMO対策の教科書

ChatGPTなどの大規模言語モデル(LLM)が普及し、情報の届け先は“検索エンジン”から“AI”へと広がっています。
こうした時代において重要なのが「AIに選ばれる」状態をつくる“LLMO(大規模言語モデル最適化)”の視点です。
本資料『LLMO対策の教科書』では、AIがブランドをどう選ぶのか、その仕組みや企業が取るべき対策、実践事例までを体系的に解説。
SEOの次に取り組むべき“次世代の最適化”を、一冊にまとめました。
AI時代における新しいSEOの入門書として、ぜひご活用ください。
関連記事



デジタルマーケティングのお悩み、
まずはお気軽にご相談ください。
サービス詳細は資料でもご確認いただけます。